
If you find this article bringing you new insight, please consider joining Patreon to show your support!
Foreword
In Hong Kong, there are so many code boot camps teaching javascript courses that market with the buzzword - Full Stack developer. In the code boot camp, the candidates are trained to figure out the frontend (React), backend (Nodejs), and database(NoSQL) in a short period. As we all know, each of these fields is a super big spectrum that takes time to discover and study. I am pretty confident to say that:
It is easy to get it working but challenging to do it right.
The root of doing the right thing is entirely relying on the fundamentals - knowledge of Software Engineering. It is a big topic that I would continue to write articles to share more.
Let's back to the topic - The javascript declarative cost.
Declarative Javascript (Functional Programming)
ES6 has introduced functional operators(.map, .filter, .reduce) for Array. I can't remember the last time I wrote "for loop" control flow to compute data in javascript.
I really like the power of declarative programming style that helps me write nearly bug-free and scalable data transformations
I decided to start building a new project called kt.ts that targeted to bring a Kotlin wise-designed collections API interface to Typescript that the existing npm modules can't compete with.
In Javascript, there are two popular FP libraries called lodash and ramda, developers write data transformations in a self-documented and declarative way.
// lodash lazy chain
_.chain(arr)
.map(someTransform)
.filter(isNotNullPredicate)
.uniq()
.sumBy(someCalculation)
.value()
// ramda
R.pipe(
R.map(someTransform),
R.filter(isNotNullPredicate),
R.uniq,
R.map(someCalculation),
R.sum,
)(array)To do the same express in Kotlin, we could express in a simpler way:
array
.mapNotNull(someTransform)
.distinct()
.sumBy(someCalculation)That's why I would like to bring these wise and practical designed interfaces from Kotlin to Typescript.
Creating kt.ts in a wrapper approach
So, I started with a wrapper approach that uses lodash internally to build the kt.ts abstractions. After a few hours of implementation and designing the project architecture, a few commonly used interfaces are finished like .mapNotNull(transform) , .distinct().
Here is an example of the wrapper approach in Typescript:
import { uniq, uniqBy } from 'lodash'
declare global {
interface Array<T> extends KtListDistinctOp<T> {}
}
export interface KtListDistinctOp<T> {
/**
* Returns a list containing only distinct elements from the given collection.
*
* The elements in the resulting list are in the same order as they were in the source collection.
*/
distinct(): T[]
/**
* Returns a list containing only elements from the given collection
* having distinct keys returned by the given [selector] function.
*
* The elements in the resulting list are in the same order as they were in the source collection.
*/
distinctBy<K>(selector: (value: T) => K): T[]
}
export default <T extends any>(proto: Array<T>) => {
proto.distinct = function (): T[] {
return uniq(this)
}
proto.distinctBy = function <R>(selector: (value: T) => R) {
return uniqBy(this, selector)
}
}After that, I kick-started another project to benchmark my wrapped implementations in kt.ts to guarantee the implementation doesn't have performance regression. I wrote the vanilla for-loop approach to compare my kt.ts implementation.
The benchmark result is very disappointed and completely unacceptable. The first thought that came to my head was
Did I do something wrong? Is that V8 optimization too magical to me? Or lodash issue?
OMFG, 80x performance difference!?
To take care of my curiosity,
my sense of software engineering summon me to implement all possible versions of.mapNotNull,.distinct, and.sumByin vanilla javascript and different libraries.
Preparation of Javascript Benchmark
To kick start, I pick a common scenario that uses .mapNotNull , .distinct , and .sumBy that use native, ramda, lodash, array prototype, and lazy iterator to implement the same data transformation logic.
Finally, I implemented 19 variations that are (click to browse the source code)
- native-ideal-while
- native-standard-for-loop
- native-fp (declarative, native
.map,.filter,.reduce) - native-fp-optimized (merged FP operators)
- native-fp-reduce-imperative(infamous wrong way of using reduce)
- lodash-one-by-one
- lodash-one-by-one-optimized
- lodash-lazy-chain
- lodash-lazy-chain-optimized
- lodash-fp
- lodash-fp-optimized
- ramda
- ramda-optimized
- array-ext-native (kt.ts designed)
- array-ext-lodash-optmized (kt.ts designed)
- array-ext-ramda-optmized (kt.ts designed)
- lazy-sequence-native
- lazy-sequence-lodash-optmized
- lazy-sequence-ramda-optmized
Then, I use benchmark npm library to run with arraySize = [1,10,100,1k,10k,100k,1M]` in node.js v14.
Those implementations are so sensitive to CPU performance.
I have to guarantee there is
- No unwanted applications are running
- No noisy neighbor on cloud
- No performance thermal throttling
- Large enough sample size to take the average
Thus, I rented a cloud-based Packet's Bare Metal Ubuntu Server (t1.small.x86). Run 1000 sample * 20 implementations * 7 size. Here is the benchmark performance:
| Machine | t1.small.x86 (bare metal) |
| CPU | 4 Physical Cores @ 2.4 GHz (1 × ATOM C2550) |
| Node | v14.9.0 |
| Linux | Ubuntu 20.04 |
| Min Sample | 1000 |
| Duration | 16.44 hours |
| Script | node --max-old-space-size=4096 src/node/perf.mjs |
| Repository | https://github.com/gaplo917/js-benchmark |
Stunning Benchmark Result
As a result, the whole benchmark 1000 sample * 20 implementations * 7 size it takes 16.44 hours to run!
Here is the result:
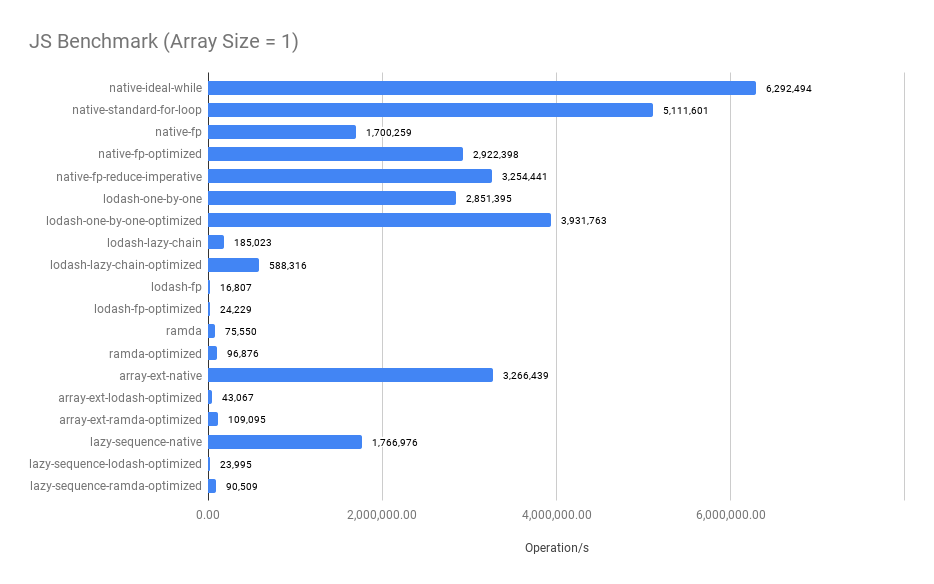
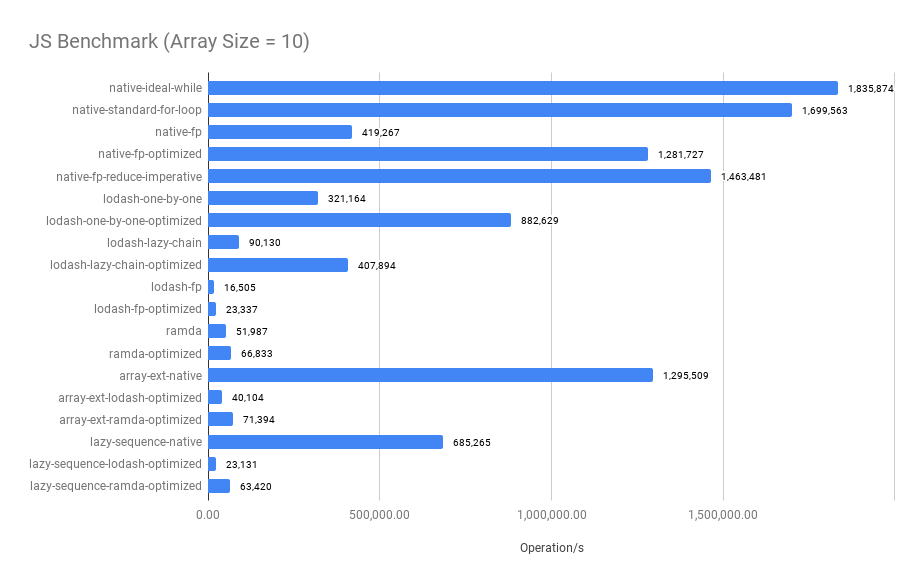
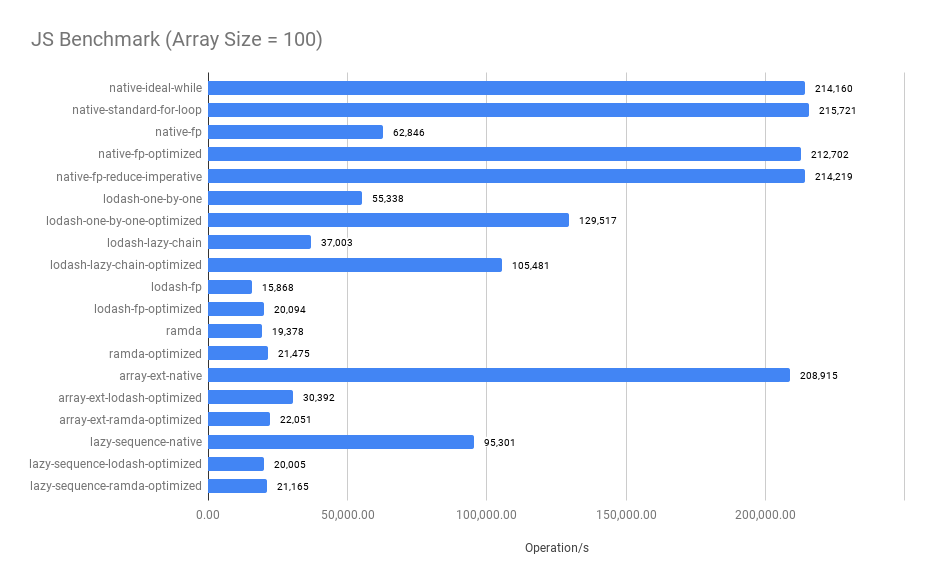
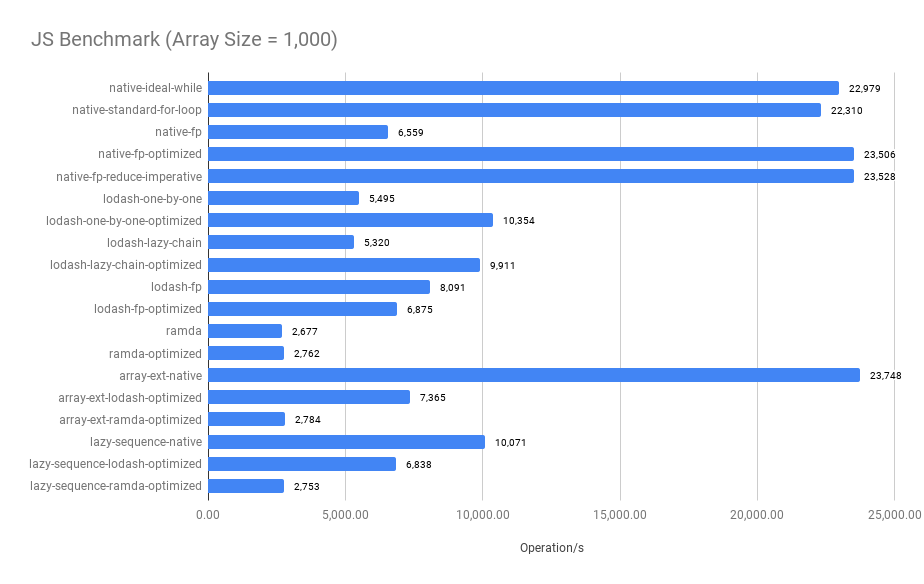
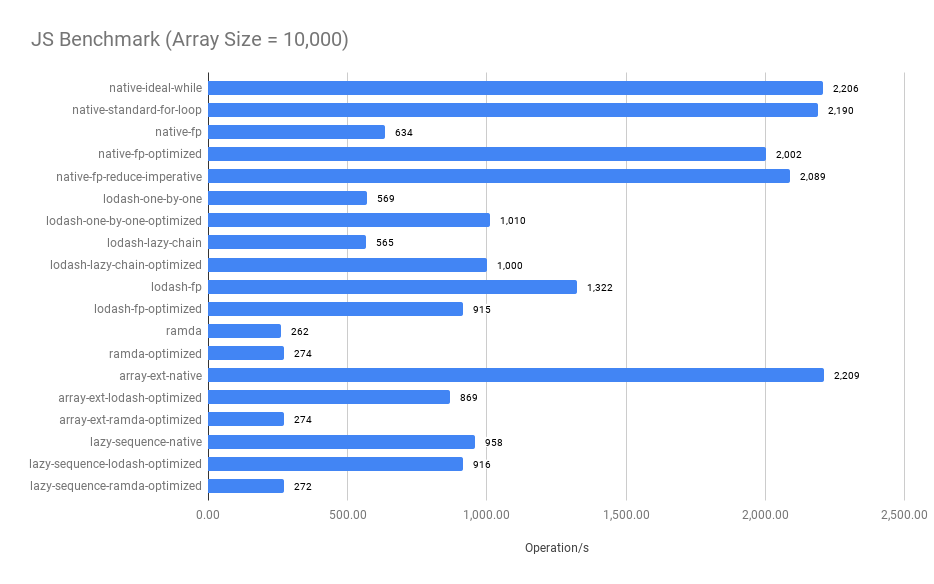
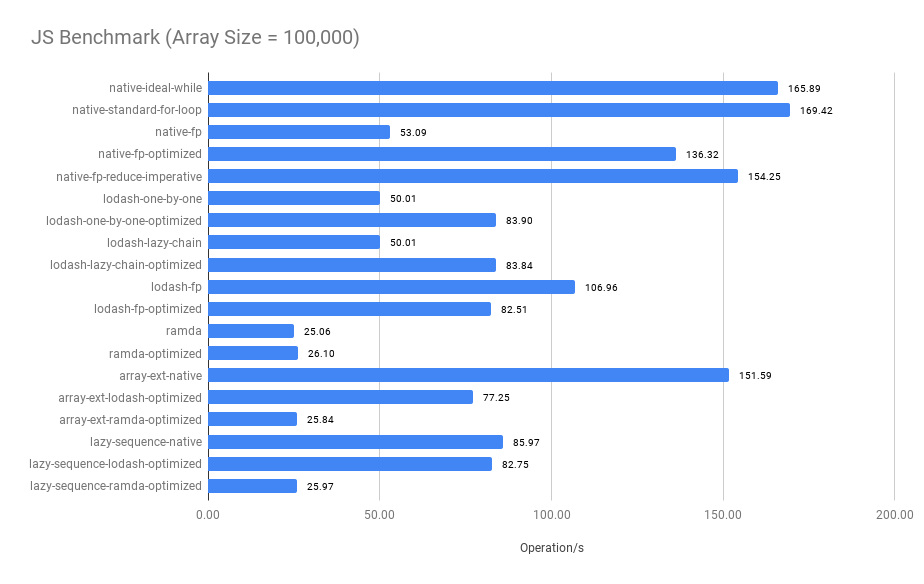
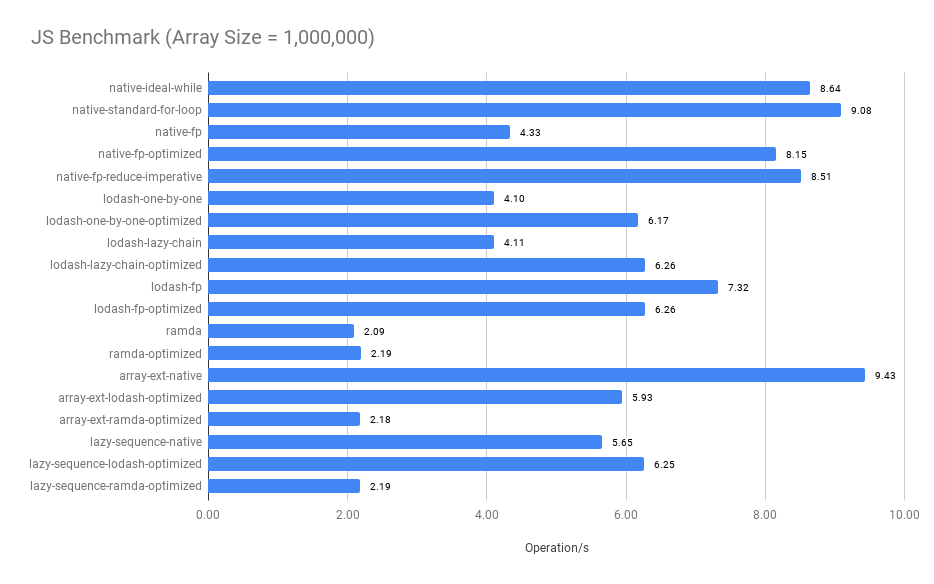
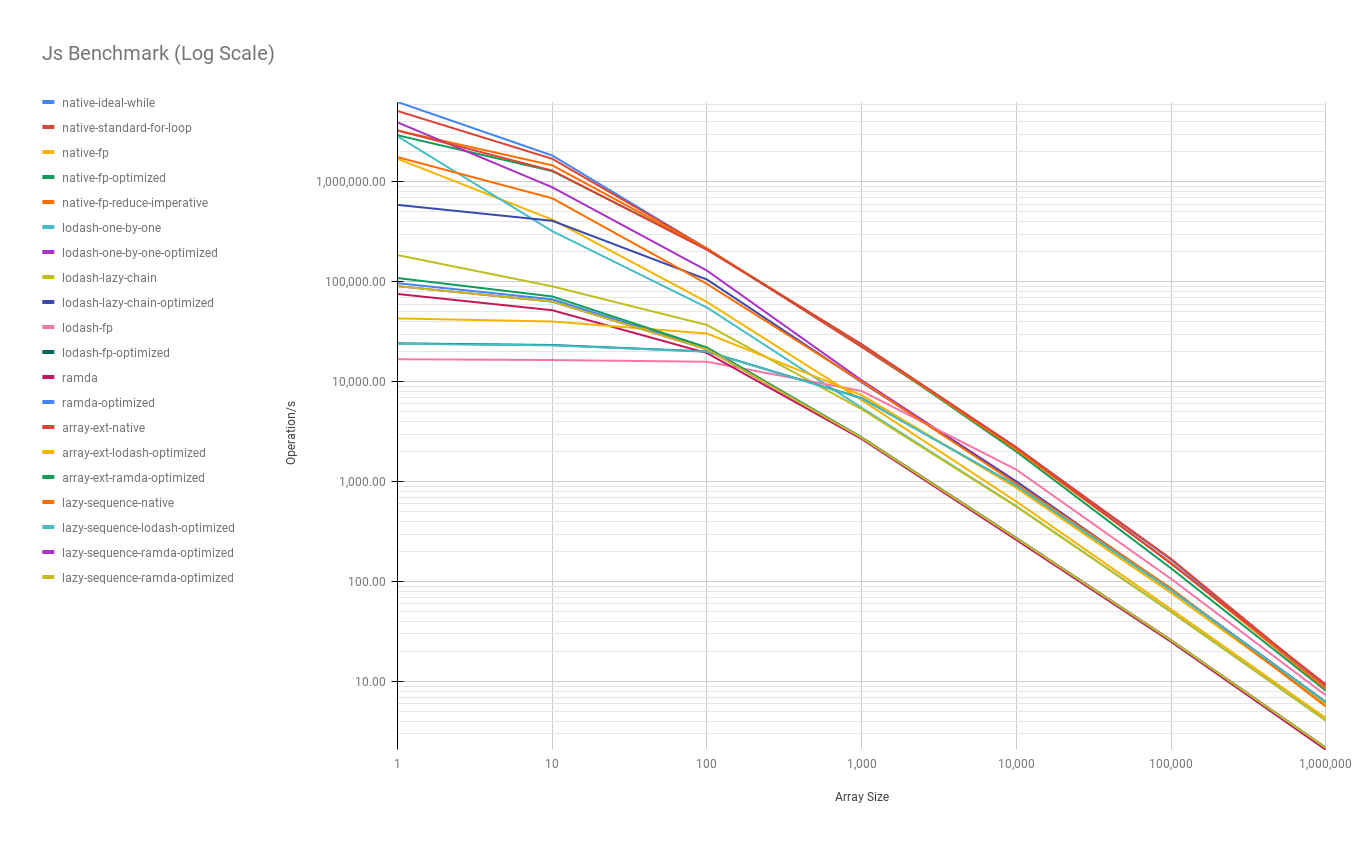
Summary:
- The imperative approach performs the best when the array size is small
- Merged functional operators significantly improve the performance, compare
native-fpandnative-fp-optimized, see the optimized codes - The bigger the array size, the closer between
native-fp-optimizedandnative-ideal-while. The performance of thenative-fp-optimizedis very close to thenative-ideal-whilewhen thearray size >= 100. - The
ramdaandlodash/fp's benchmark results are surprisingly worse when thearray size < 100 - Surprisingly, comparing between
native-standard-for-loopandarray-ext-native,array-ext-nativeis a declarative abstraction that uses twoforloop implementations and onenew Setunderlying to avoidSetthe operation does improve the performance when the array size is large.
// native-standard-for-loop
export function nativeStandard(arr) {
const len = arr.length
if (len === 0) {
return 0
}
const set = new Set()
let sum = 0
for (let i = 0; i < len; i++) {
const e = someTransform(arr[i])
if (e !== null) {
const oriSize = set.size
set.add(e)
if (set.size !== oriSize) {
sum += someCalculation(e)
}
}
}
return sum
}
// array-ext-native
export function arrayExtensionNative(arr) {
return arr
.ktMapNotNullNative(someTransform)
.ktDistinctNative()
.ktSumByNative(someCalculation)
}
Array.prototype.ktMapNotNullNative = function (transform) {
const result = []
for (let i = 0, len = this.length; i < len; i++) {
const e = transform(this[i])
if (e !== null) {
result.push(e)
}
}
return result
}
Array.prototype.ktDistinctNative = function () {
return Array.from(new Set(this))
}
Array.prototype.ktSumByNative = function (selector) {
let sum = 0
for (let i = 0, len = this.length; i < len; i++) {
sum += selector(this[i])
}
return sum
}The benchmark proves that if kt.ts can bring Kotlin collection API design(lots of extra declarative operators) to Typescript, Typescript developers can
- enjoy shorter implementation and more performant declarative codes compared with the
native-fp/lodash/ramda - enjoy a lot of extra declarative operators (merged multiple functional operators) to build different use cases
I believe 80%+ of worldwide javascript usage won't process an array having more than 1k items, and 80%+ developers won't choose javascript to build performance-sensitive applications.
A professional software engineer should always know their needs.
Don't worry about non-exist needs.
If the performance is critical in most use cases, I suggest learning the necessary algorithms and data structures and writing them in an imperative style(control flow) to get the best performance rather than spending time struggling on the performance tuning of the declarative programming style.
If the performance is neglectable in most use cases, I suggest going for declarative programming style to use well-tested functional operators to write a more readable and self-documented data transformation logic.
Conclusion
By kicking start a new side project, kt.ts, I learned a lot from creating this benchmark of figuring out the javascript declarative cost. This benchmark has changed my mind about using lodash or ramda as a foundation library.
Learning lodash or ramda is just a way to work in a more functional and declarative. They did provide well-tested functional operators and allowed developers to use them immediately. However, from the benchmark result, the implementation itself doesn't work efficiently in javascript compared to the native functional operators.
Unless their internal implementations would eventually provide a "Parallel Processing" option that spawns an extra node worker/web worker and process array elements in parallel, like Scala's parallel collection, otherwise, under a single main thread execution model, you need to sacrifice some performance to trade readability and development speed.
That is the "Declarative Cost in Javascript".
If someone told you a simple .map or .filter operator in lodash or ramda is just n% slower than the native .map or .filter operator, they forget that we normally chain 3 - 5 operators on average that is (1-n)^k % slower.
If on average n = 0.2, chain 3 - 5 operators become
- 0.8^3 = 0.51
- 0.8^5 = 0.32
~50-70% performance drop on average
if
chaining 3 - 5 operators
I hope you can get some insight from this article!
Patreon Backers
Thank you for being so supportive ❤️❤️❤️. Your support made this R&D article always free, open, and accessible. It also allows me to focus on my writings that bring a positive impact to you and the other readers among the global technical community. Become a Patreon Backer!
Backers:
-

- Anthony Siu (Gold)
- Martin Ho (Gold)
- Chan Paul (Gold)
- Jay Chau (Gold)
- Mat (Gold)
- Raymond An
- Chi Hang Chan


